
InstantSplat, DUSt3R
InstantSplat, DUSt3R

Stream Summary
Well, that was a wild ride through the cosmos of computer vision, wasn’t it? We’ve journeyed from the clunky, hand-crafted contraptions of yesteryear’s structure from motion pipelines to the sleek, learned elegance of InstantSplat and its trusty sidekick, Duster. It’s like swapping a horse-drawn carriage for a spaceship, and who wouldn’t want to travel at warp speed?
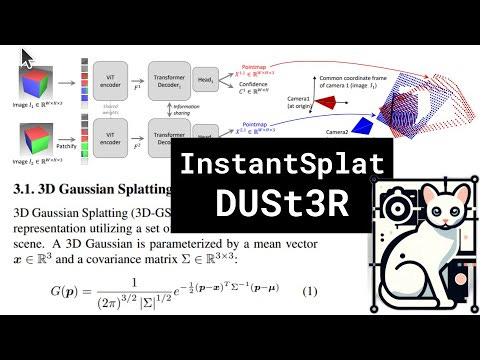
InstantSplat is the new kid on the block, making waves by fusing the power of neural fields with the interpretability and composability of explicit 3D representations. It’s like having your cake and eating it too, without the need for obscure, hard-coded rules and a mountain of training images.
Duster, the unsung hero of this saga, takes center stage by sidestepping the tedious camera calibration dance. It simply observes a scene from multiple angles and, with the wisdom of a seasoned space explorer, deduces the camera positions and a rough 3D sketch. This initial map then guides InstantSplat, allowing it to focus its efforts on refining the details and producing a stunning 3D reconstruction.
It’s a match made in the heavens of computer vision, folks. This dynamic duo has left traditional methods in the dust, achieving state-of-the-art results on a plethora of tasks, from depth estimation to pose estimation, all while being faster and more user-friendly.
So, whether you’re a seasoned computer vision veteran or a curious newcomer, InstantSplat and Duster are here to make your 3D dreams a reality. So buckle up, grab your yerba mate (or coffee, if you prefer), and prepare to explore the vast universe of 3D possibilities with these revolutionary tools!
Paper Abstracts
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds (http://arxiv.org/pdf/2403.20309v1)
While novel view synthesis (NVS) has made substantial progress in 3D computer
vision, it typically requires an initial estimation of camera intrinsics and
extrinsics from dense viewpoints. This pre-processing is usually conducted via
a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and
unreliable, particularly in sparse-view scenarios with insufficient matched
features for accurate reconstruction. In this work, we integrate the strengths
of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with
end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved
issues in NVS under unconstrained settings, which encompasses pose-free and
sparse view challenges. Our framework, InstantSplat, unifies dense stereo
priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview &
pose-free images in less than 1 minute. Specifically, InstantSplat comprises a
Coarse Geometric Initialization (CGI) module that swiftly establishes a
preliminary scene structure and camera parameters across all training views,
utilizing globally-aligned 3D point maps derived from a pre-trained dense
stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO)
module, which jointly optimizes the 3D Gaussian attributes and the initialized
poses with pose regularization. Experiments conducted on the large-scale
outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly
improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error
(ATE) by 80%. These establish InstantSplat as a viable solution for scenarios
involving posefree and sparse-view conditions. Project page:
instantsplat.github.io.
DUSt3R: Geometric 3D Vision Made Easy (http://arxiv.org/pdf/2312.14132v1)
Multi-view stereo reconstruction (MVS) in the wild requires to first estimate
the camera parameters e.g. intrinsic and extrinsic parameters. These are
usually tedious and cumbersome to obtain, yet they are mandatory to triangulate
corresponding pixels in 3D space, which is the core of all best performing MVS
algorithms. In this work, we take an opposite stance and introduce DUSt3R, a
radically novel paradigm for Dense and Unconstrained Stereo 3D Reconstruction
of arbitrary image collections, i.e. operating without prior information about
camera calibration nor viewpoint poses. We cast the pairwise reconstruction
problem as a regression of pointmaps, relaxing the hard constraints of usual
projective camera models. We show that this formulation smoothly unifies the
monocular and binocular reconstruction cases. In the case where more than two
images are provided, we further propose a simple yet effective global alignment
strategy that expresses all pairwise pointmaps in a common reference frame. We
base our network architecture on standard Transformer encoders and decoders,
allowing us to leverage powerful pretrained models. Our formulation directly
provides a 3D model of the scene as well as depth information, but
interestingly, we can seamlessly recover from it, pixel matches, relative and
absolute camera. Exhaustive experiments on all these tasks showcase that the
proposed DUSt3R can unify various 3D vision tasks and set new SoTAs on
monocular/multi-view depth estimation as well as relative pose estimation. In
summary, DUSt3R makes many geometric 3D vision tasks easy.
This content was generated by gemini-1.5-pro-latest on 2024–04–10. Find more Hu-Po content on:
youtube.com/@hu-po
twitter.com/hupobuboo
twitch.tv/hu_po
discord.gg/pPAFwndTJd
substack.com/@hupo
reddit.com/r/hupos/
linkedin.com/in/hugoponte/
tiktok.com/@hu.po.ai
patreon.com/user?u=89667142
hu-po.medium.com
researchhub.com/user/986081/overview
hu-po.github.io/